
Rendering PDFs on Vercel with Next.js
Vercel increased the 250MB function bundle limit mentioned in this article to 5GB on June 30, 2026. This would allow you to run the full browser automation dependencies of Puppeteer in a single bundle. The described solution with chromium-min is still valid and keeps your function bundle size low.
Rendering PDFs in a serverless environment is a challenging task. Serverless functions are stateless. That means there is no persistent disk between invocations, no shared filesystem, and no long-running browser process you can keep open between requests. Puppeteer expects a local Chromium binary, but on Vercel there is no "local" anything.
For the AWISTA waste management portal, we need to render tens of thousands of waste calendar PDFs on demand. Each address in Düsseldorf gets its own personalized calendar with collection dates for that specific address. The PDFs are layout-heavy, depend on data from the database, and have to be available reliably.
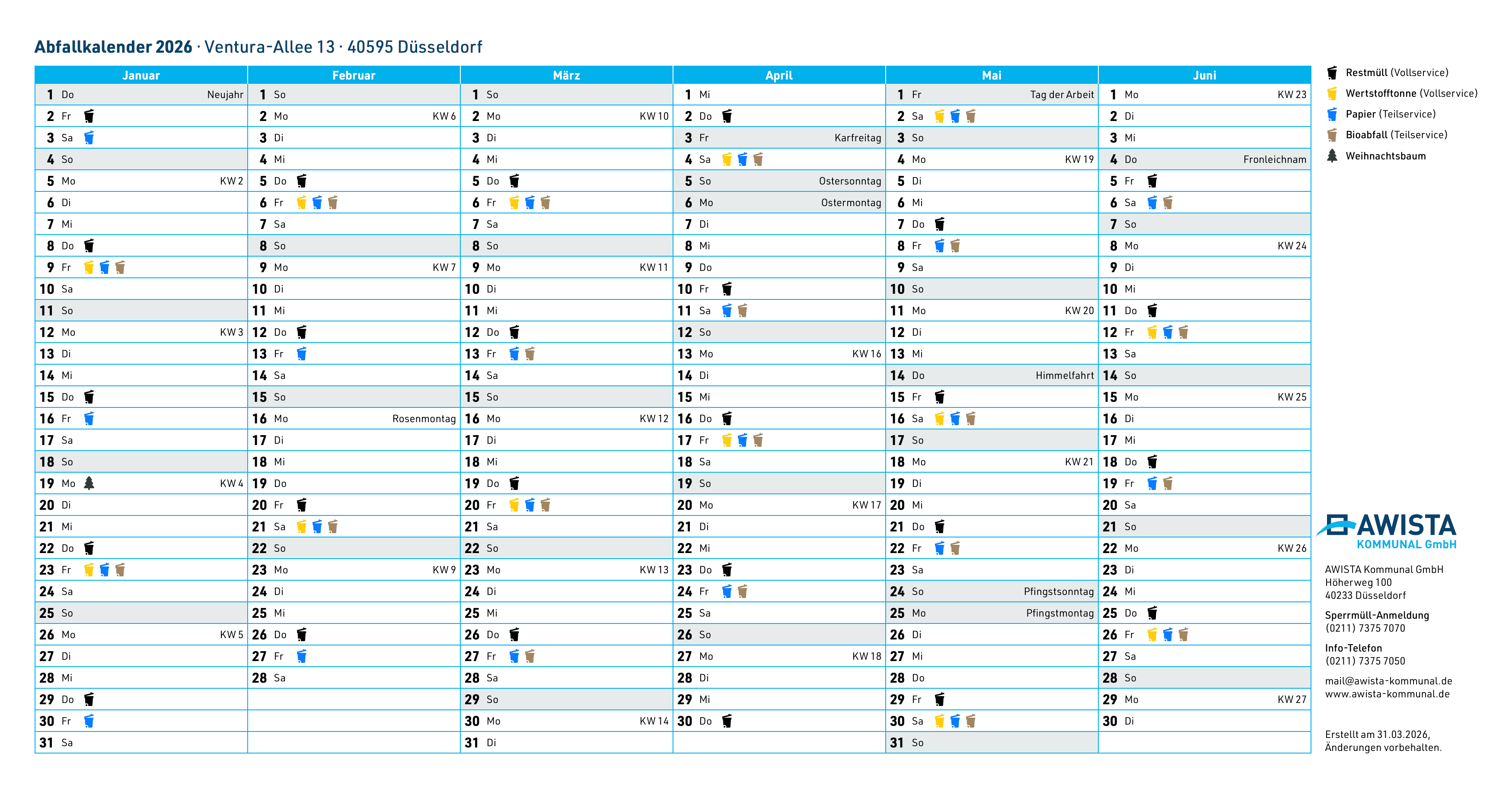
Getting this bulletproof took longer than I expected.
The first version used a third-party PDF rendering service. It was too slow, too expensive, and gave me almost no control over caching. I switched to Cloudflare Browser Rendering with Durable Objects and KV caching, which worked in principle, but the worker frequently failed to connect to the template page URL (hosted on Vercel). After enough flaky errors I gave up trying to debug it (Whether this had anything to do with the ongoing beef between Vercel and Cloudflare, I'll never know. By the way, the rendered PDFs in this project are cached in Cloudflare R2, so this isn't an anti-Cloudflare post.)
I ended up with a Next.js Route Handler running Puppeteer on Vercel. It works reliably now, but the path to a working setup involves several non-obvious pitfalls.
The 250MB problem
Vercel functions have a default 250MB bundle size limit. The standard puppeteer package bundles its own Chromium binary and blows past that limit immediately.
The solution is to split Puppeteer from Chromium:
puppeteer-core: a lightweight version of Puppeteer without a bundled browser@sparticuz/chromium-min: a minimal, community-maintained Chromium build small enough to fit Vercel's constraints
@sparticuz/chromium-min doesn't include the actual Chromium binary in the npm package. Instead, it downloads the binary at runtime from a URL you provide. You host the chromium-pack.tar file somewhere (like in /public of the Next.js app itself) and pass that URL to the chromium loader.
Caching the executable path
On the first request, the function downloads the Chromium binary and extracts it to a temporary directory. That's a one-time cost per function instance, but if you don't cache the result, every request pays it. On a cold start that means several hundred milliseconds of overhead before any rendering happens.
The fix is a module-level variable that survives between requests on the same warm instance:
let cachedExecutablePath: string | null = null
Module-level state in serverless functions is preserved as long as the instance stays warm. The first request populates the cache, subsequent requests on the same instance read from it directly.
Preventing concurrent downloads
There's a subtler problem. When a cold function gets multiple parallel requests, each one calls executablePath() independently and tries to download Chromium. You end up with several concurrent downloads racing each other, all writing to the same temp directory. At best this wastes bandwidth. At worst it corrupts the binary.
The fix is to share a single download promise across all requests:
let downloadPromise: Promise<string> | null = null
async function getChromiumPath(): Promise<string> {
if (cachedExecutablePath) return cachedExecutablePath
if (!downloadPromise) {
const chromium = (await import('@sparticuz/chromium-min')).default
downloadPromise = chromium
.executablePath(CHROMIUM_PACK_URL)
.then((path) => {
cachedExecutablePath = path
return path
})
.catch((error) => {
downloadPromise = null
throw error
})
}
return downloadPromise
}
Now the first request kicks off the download, every parallel request awaits the same promise, and only one download actually happens. If it fails, the promise is cleared so the next request can retry.
The full implementation
Putting it together, here's the complete Route Handler. It also handles the local development case, where you want the regular puppeteer package with its bundled Chromium instead of the binary download dance:
import type { NextRequest } from 'next/server'
import type { Browser, LaunchOptions } from 'puppeteer-core'
// URL to the Chromium binary package hosted in `/public`.
// Tip: you can host the chromium-pack.tar file elsewhere
const CHROMIUM_PACK_URL = `https://${process.env.VERCEL_PROJECT_PRODUCTION_URL}/chromium-pack.tar`
// Cache the Chromium executable path to avoid re-downloading on subsequent requests
let cachedExecutablePath: string | null = null
let downloadPromise: Promise<string> | null = null
// Based on https://github.com/gabenunez/puppeteer-on-vercel
async function getChromiumPath(): Promise<string> {
if (cachedExecutablePath) return cachedExecutablePath
// Prevent concurrent downloads by reusing the same promise
if (!downloadPromise) {
const chromium = (await import('@sparticuz/chromium-min')).default
downloadPromise = chromium
.executablePath(CHROMIUM_PACK_URL)
.then((path) => {
cachedExecutablePath = path
return path
})
.catch((error) => {
downloadPromise = null
throw error
})
}
return downloadPromise
}
export async function GET(request: NextRequest) {
const { searchParams } = new URL(request.url)
const templateUrl = searchParams.get('url')
if (!templateUrl) {
return new Response('Please provide a template URL.', { status: 400 })
}
const isVercel = !!process.env.VERCEL_ENV
let browser: Browser | undefined
try {
let puppeteer: typeof import('puppeteer') | typeof import('puppeteer-core') | undefined
let launchOptions: LaunchOptions = {
headless: true,
}
if (isVercel) {
const chromium = (await import('@sparticuz/chromium-min')).default
puppeteer = await import('puppeteer-core')
const executablePath = await getChromiumPath()
launchOptions = {
...launchOptions,
args: chromium.args,
executablePath,
}
} else {
puppeteer = await import('puppeteer')
}
browser = await puppeteer.launch(launchOptions)
const page = await browser.newPage()
await page.goto(templateUrl.toString(), { waitUntil: 'networkidle2' })
const pdf = await page.pdf({ printBackground: true, format: 'A4', landscape: true })
await page.close()
if (!pdf) throw new Error(`Failed to generate PDF from URL ${templateUrl}`)
return new Response(Buffer.from(pdf), {
headers: {
'Content-Type': 'application/pdf',
'Content-Disposition': `inline; filename="calendar.pdf";`,
},
})
} catch (error) {
console.error(error)
return new Response('Internal Server Error', { status: 500 })
} finally {
if (browser) {
await browser.close()
}
}
}
The await browser.close() in the finally block is important. Forgetting to close the browser leaves Chromium processes running, which on a serverless instance means burning memory.
What about caching the rendered PDFs?
Generating a PDF takes a few hundred milliseconds at minimum, often more. We don't want to render the same calendar twice, both for the user experience and to avoid burning compute on work we've already done. For AWISTA, the rendered PDFs are cached in Cloudflare R2, keyed by address. The first request for a given address generates and stores the PDF. Every subsequent request serves it directly from R2. The Puppeteer route only runs on cache misses.
Whether you use R2, S3, Vercel Blob, or any other object storage doesn't really matter. What matters is that PDF generation should never be on the hot path of a normal user request. Generate once, cache, serve from cache.
If you've been fighting with serverless PDF rendering and bouncing between third-party services, this approach is worth trying. The setup looks intimidating because of the binary download process, but once it's wired up, it's stable and cheap to run.